
L’IA promet beaucoup… mais la réalité est plus nuancée
Aujourd’hui, les projets d’intelligence artificielle sont au cœur de toutes les stratégies data.
Améliorer la prévision commerciale, détecter les anomalies, automatiser la prise de décision, personnaliser l’expérience client…
Sur le papier, les cas d’usage sont puissants.
Mais sur le terrain ?
👉 83 % des projets IA échouent, selon McKinsey.
Et non, ce n’est pas parce que les modèles ne sont pas bons, ou que l’outil choisi est mauvais.
C’est beaucoup plus simple – et plus structurant :
le socle de données n’est pas prêt.
Les vraies causes des échecs IA : côté données
Une IA apprend uniquement à partir des données qu’on lui fournit.
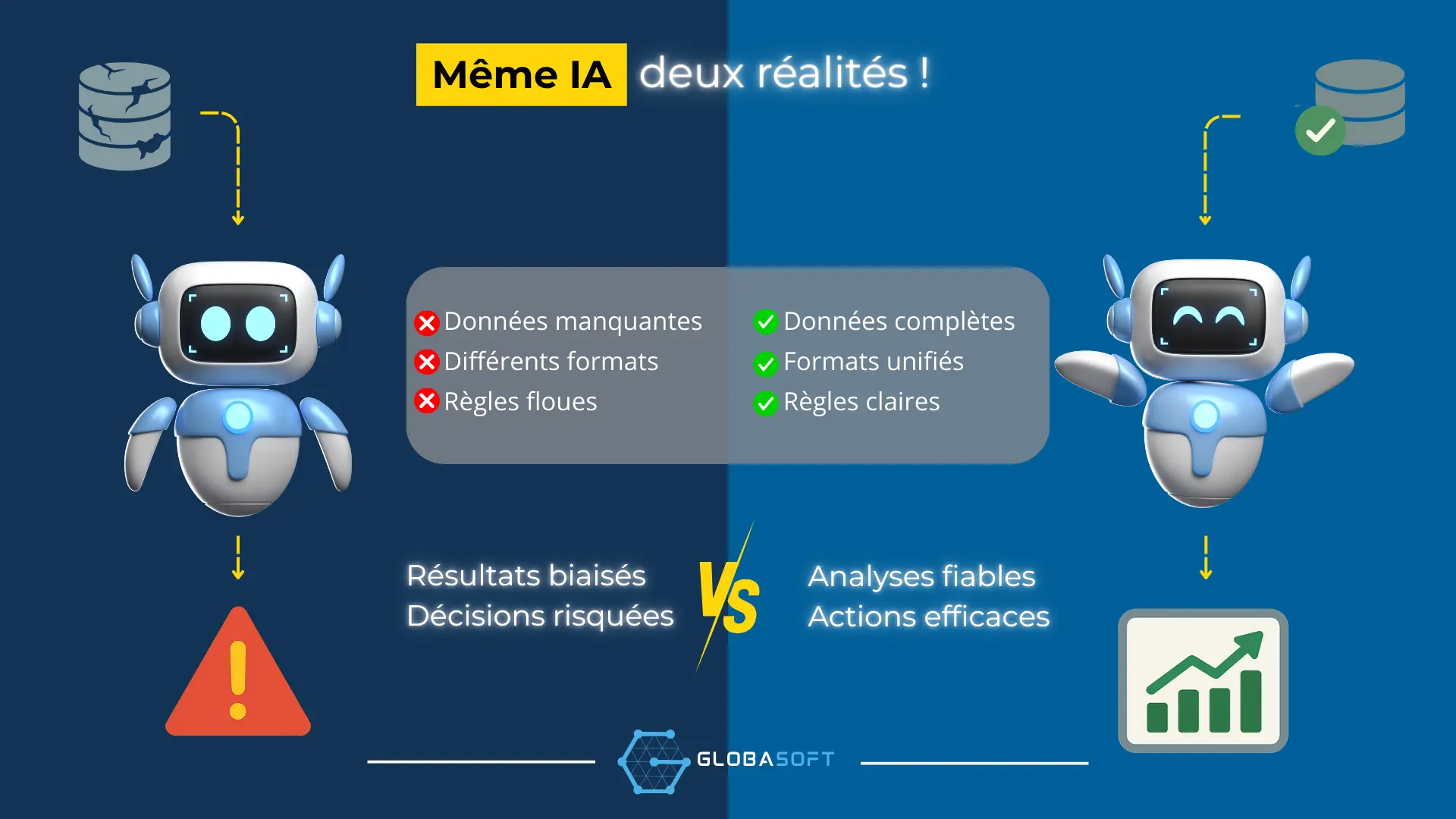
Si la qualité, la cohérence, la structure ou la gouvernance de ces données est défaillante…
le modèle ne peut que produire des résultats biaisés, incomplets, ou carrément inutilisables.
Voici les principales causes invisibles qui mettent à mal les projets IA dès les premières phases :
1. Des données incomplètes ou peu exploitables
- Champs vides sur des sources clés
- Informations critiques non renseignées (ex. statuts, dates, catégories)
- Absence d’un historique exploitable (données trop récentes ou mal versionnées)
2. Une absence de structuration claire
- Données non normalisées (formats, typologies, unités, codifications)
- Aucune règle de validation ou de vérification métier
- Mauvaise gestion des cas particuliers (valeurs nulles, doublons, erreurs de saisie)
3. Des référentiels mal alignés
- Incohérences entre systèmes (ERP vs CRM vs fichiers métier)
- Définitions floues ou contradictoires des entités de base (client, produit, projet)
- Données entrées différemment selon les services
4. Une gouvernance trop faible
- Accès trop larges ou non maîtrisés
- Évolutions non documentées
- Prolifération de fichiers Excel “cachés” qui échappent à tout contrôle
Ce que l’IA amplifie… c’est la base que vous lui servez
On a souvent tendance à croire que l’IA est “intelligente” au sens humain.
Mais en réalité, c’est un amplificateur : elle apprend uniquement à partir des données qu’on lui fournit.
Une IA ne sait pas si votre fichier est fiable.
Elle ne fait pas la différence entre un champ bien rempli et un champ deviné.
Elle n’interprète pas vos doublons… elle les assimile.
👉 C’est pourquoi un projet IA bien mené commence toujours par un vrai projet data.
Comment fiabiliser votre socle data avant de lancer l’IA ?
Voici les actions à mener en amont de toute modélisation IA :
1. Cartographier les sources de données
- Quelles sont les bases réellement utilisées par les équipes ?
- D’où viennent les données clés ?
- À quelle fréquence sont-elles mises à jour ?
2. Identifier les champs critiques pour vos cas d’usage
- Quels champs influencent les décisions (score, statut, canal, etc.) ?
- Sont-ils toujours renseignés ? À quel niveau de qualité ?
- Sont-ils homogènes entre les services ?
3. Structurer les règles métier
- Validation des formats (dates, emails, codes)
- Gestion des doublons (clé de correspondance, outil de déduplication)
- Normalisation des valeurs (catégories, statuts, unités…)
4. Mettre en place des contrôles automatiques
- Flows, scripts ou traitements planifiés
- Alerte en cas d’anomalie de remplissage
- Blocages sur certains champs ou valeurs incohérentes
5. Limiter les accès en écriture
- Trop d’erreurs proviennent de saisies humaines non encadrées
- Il est essentiel de filtrer qui modifie quoi, et dans quelles conditions
L’IA n’est pas magique. Elle est exigeante.
Ce qui fait la performance d’un modèle IA, ce n’est pas seulement l’algorithme.
C’est la qualité du carburant qu’on lui donne.
Et ce carburant, c’est votre data.
📌 Si vous partez sur un socle flou, instable, mal aligné…
ne vous étonnez pas si vos modèles n’apportent pas la performance attendue.
Garbage in → Garbage out.
Toujours.
Besoin d’un audit de votre socle data avant IA ?
Chez Globasoft, nous aidons les entreprises à structurer leur socle de données avant de lancer un projet IA.
Nous intervenons sur :
- L’évaluation de la qualité et de la gouvernance des données
- La définition des cas d’usage prioritaire et des champs critiques
- La mise en place des contrôles et processus nécessaires
- Le tout avec un engagement de résultat, adapté à vos enjeux métier
ou découvrez nos autres articles pour structurer votre démarche data.